
シンガポール、2025年7月5日 /PRNewswire/ — 2024年9月、SkyworkはSkywork-Rewardシリーズモデルと関連データセットを初めてオープンソース化しました。過去9ヶ月間、これらのモデルとデータはオープンソースコミュニティで研究と実践に広く応用され、HuggingFaceプラットフォームでの累計ダウンロード数は75万回を超え、RewardBenchなどの権威ある評価において複数の最先端モデルが優秀な成績を収めることを支援しました。
2025年7月4日、Skyworkは第2世代報酬モデル(Reward Model)であるSkywork-Reward-V2シリーズを継続してオープンソース化しました。これは異なるベースモデルと異なるサイズに基づく8つの報酬モデルを含み、パラメータ規模は6億から80億まで様々で、7つの主要な報酬モデル評価ランキングで全面的に首位を獲得しました。
Skywork-Reward-V2 ダウンロードアドレス
HuggingFace アドレス:
https://huggingface.co/collections/Skywork/skywork-reward-v2-685cc86ce5d9c9e4be500c84
GitHub アドレス:
https://github.com/SkyworkAI/Skywork-Reward-V2
技術報告書:
https://arxiv.org/abs/2507.01352
報酬モデルは人間フィードバックからの強化学習(RLHF)プロセスにおいて極めて重要な役割を果たします。この新世代報酬モデルの構築過程において、我々は合計4000万対の選好対比を含む混合データセットSkywork-SynPref-40Mを構築しました。
大規模で効率的なデータスクリーニングとフィルタリングを実現するため、Skyworkは特に人機協働の2段階フローを設計し、人工アノテーションの高品質とモデルの大規模処理能力を組み合わせました。このフローにおいて、人間は厳格に検証された高品質アノテーションを提供し、大規模言語モデル(LLM)は人間の指導に基づいて自動的に整理と拡充を行います。
上記の優質な混合選好データに基づいて、我々はSkywork-Reward-V2シリーズを開発しました。これは広範な適用性を示し、複数の能力次元において優秀な性能を発揮します。これには人間選好への一般的な整合性、客観的正確性、安全性、スタイルバイアスへの抵抗能力、およびbest-of-N拡張能力が含まれます。実験検証により、このシリーズのモデルは7つの主要な報酬モデル評価ベンチマークで最高性能を獲得しました。
01 Skywork-SynPref-40M :人機協働による千万級人間選好データスクリーニング
現在最も先進的なオープンソース報酬モデルでも、大多数の主要評価ベンチマークでの性能は依然として不十分です。これらは人間選好の細かく複雑な特徴を効果的に捉えることができず、特に多次元、多層レベルのフィードバックに直面した際の能力は特に限定的です。
さらに、多くの報酬モデルは特定のベンチマークタスクで優秀な性能を示しやすいものの、新しいタスクや新しいシナリオへの移行が困難で、明らかな「過学習」現象を示します。既存の研究では目的関数の最適化、モデルアーキテクチャの改善、および最近注目されている生成型報酬モデル(Generative Reward Model)などの方法により性能向上を試みていますが、全体的な効果は依然として非常に限定的です。
我々は現在の報酬モデルの脆弱性は主に既存の選好データセットの限界に起因すると考えます。これらのデータセットはしばしばカバー範囲が限定的で、ラベル生成方式が比較的機械的であったり、厳格な品質管理が欠けていたりします。
そのため、新世代報酬モデルの研究開発において、我々は第1世代モデルのデータ最適化での経験を継承するだけでなく、より多様で規模の大きい真の人間選好データを導入し、データ規模の向上と同時にデータ品質の両立を目指します。

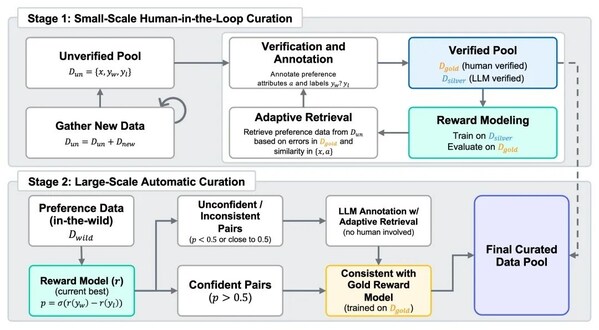
「人機協働、2段階反復」データ選別パイプライン
そのため、SkyworkはSkywork-SynPref-40Mを提案しました。これは現在までで最大規模の選好混合データセットであり、合計4000万対の選好サンプルを含みます。そのコア革新は「人機協働、2段階反復」データ選別パイプラインにあります。
第 1 段階:人間主導の小規模高品質選好構築
チームはまず未検証の初期選好プールを構築し、大規模言語モデル(LLM)を活用して選好関連の補助属性(タスクタイプ、客観性、議論性など)を生成しました。この基盤の上で、人工アノテーターは厳格な検証プロトコルに従い、外部ツールと先進的な大規模言語モデルを活用して部分データの精密な審査を行い、最終的に小規模だが高品質な「ゴールドスタンダード」データセットを構築し、後続のデータ生成とモデル評価の依拠としました。
続いて、我々はゴールドスタンダードデータの選好ラベルを指導として、LLMの大規模生成による高品質な「シルバースタンダード」データと組み合わせ、データ量の拡張を実現しました。チームはまた多回の反復最適化を実施しました:各回において、報酬モデルを訓練し、ゴールドスタンダードデータでの性能に基づいてモデルの弱点を特定;さらに類似サンプルの検索と複数モデル一致性機構による自動アノテーションにより、シルバースタンダードデータをさらに拡張・強化しました。この人機協働の閉ループプロセスは継続的に反復し、報酬モデルの選好理解と判別能力を効果的に向上させました。
第 2 段階:全自動大規模選好データ拡張
初期高品質モデルを獲得した後、第2段階は自動化された大規模データ拡張に転じます。この段階では人工審査に依存せず、訓練完了した報酬モデルによる一致性フィルタリングを採用します:
- あるサンプルのラベルが現在の最適モデル予測と一致しない場合、またはモデルの信頼度が低い場合、LLMを呼び出して再自動アノテーションを実行;
- サンプルラベルが「ゴールドモデル」(人工データのみで訓練されたモデル)予測と一致し、現在のモデルまたはLLMのサポートを得た場合、直接スクリーニングを通過可能。
この機構により、チームは元の4000万サンプルから2600万条の精選データのスクリーニングに成功し、人工アノテーション負担を大幅に削減すると同時に、選好データの規模と品質間の良好なバランスを実現しました。
02 Skywork-Reward-V2 :小モデルサイズで大モデル性能を全方位的にマッチング
前世代のSkywork-Rewardと比較して、Skyworkが新たに発表したSkywork-Reward-V2シリーズは、Qwen3とLLaMA3シリーズモデルに基づいて訓練された8つの報酬モデルを提供し、パラメータ規模は6億から80億をカバーします。
Reward Bench v1/v2、PPE Preference & Correctness、RMB、RM-Bench、JudgeBenchなど合計7つの主要報酬モデル評価ベンチマークにおいて、Skywork-Reward-V2シリーズは全面的に現在の最適(SOTA)レベルに到達しました。
データ品質と豊富さでモデル規模制限を補完
最小モデルのSkywork-Reward-V2-Qwen3-0.6Bでさえ、その全体性能は既に前世代最強モデルのSkywork-Reward-Gemma-2-27B-v0.2の平均レベルにほぼ到達しています。最大規模のSkywork-Reward-V2-Llama-3.1-8Bは、すべての主要ベンチマークテストで全面的な超越を実現し、現在全体性能が最優秀のオープンソース報酬モデルとなりました。
多次元人間選好能力の広範囲カバー
さらに、Skywork-Reward-V2は複数の高度能力評価で先進的な成績を収めました:Best-of-N(BoN)タスク、バイアス抵抗能力テスト(RM-Bench)、複雑指示理解および真実性判断(RewardBench v2)を含み、優秀な汎化能力と実用性を示しました。
高い拡張性を持つデータスクリーニングプロセス、報酬モデル性能を大幅向上
性能評価での優秀な表現に加えて、チームは「人機協働、2段階反復」データ構築フローにおいて、精密なスクリーニングとフィルタリングを経た選好データが、複数回の反復訓練において継続的に効果的に報酬モデルの全体性能を向上させることができ、特に第2段階の全自動データ拡張において特に顕著な性能を示すことを発見しました。
対照的に、元データを盲目的に拡充するだけでは初期性能を向上させることができないだけでなく、ノイズを導入して負の影響をもたらす可能性があります。データ品質の重要な役割をさらに検証するため、我々は早期版本の1600万条データサブセットで実験を行い、結果として、その中のわずか1.8%(約29万条)の高品質データを使用して8B規模モデルを訓練するだけで、その性能は既に現在の70B級SOTAリワードモデルを上回ることが示されました。この結果は再びSkywork-SynPrefデータセットが規模面で先進的地位にあるだけでなく、データ品質面でも顕著な優位性を持つことを証明しています。
03 オープンソース報酬モデルの新マイルストーンを迎える:未来 AI 基盤インフラ構築を支援
本回の第2世代報酬モデルSkywork-Reward-V2の研究作業において、チームはSkywork-SynPref-40M(4000万個の選好対を含むデータ混合集、その中2600万対は精密スクリーニング済み)、およびSkywork-Reward-V2(最先端性能を持つ8つの報酬モデルシリーズ、広範囲タスクに適用可能な設計目標)を提案しました。
我々はこの研究作業と報酬モデルの継続的反復が、オープンソース報酬モデルの発展を推進し、人間フィードバックからの強化学習(RLHF)研究の進歩をより広範囲に促進することに役立つと確信しています。これは該当分野の重要な前進であり、オープンソースコミュニティの繁栄をさらに加速させることができます。
Skywork-Reward-V2シリーズモデルは選好データ規模拡張の研究に特化しており、今後チームの研究範囲は段階的に他の未充分探索領域、例えば代替訓練技術とモデリング目標などにも拡大する予定です。
同時に、近年の分野内発展傾向を考慮すると──報酬モデルと報酬形成機構は既に今日の大規模言語モデル訓練フローの核心要素となっており、これは人間選好学習と行動誘導に基づくRLHFだけでなく、数学、プログラミングまたは一般推論タスクを含むRLVRおよびエージェントベースの学習シナリオにも適用されます。
したがって、将来我々は報酬モデルまたはより広義の統一報酬システムが、AI基盤インフラの核心を構成することを期待しています。それらはもはや単なる行動や正確性の評価器ではなく、知能システムが複雑環境で航行する「コンパス」となり、人間価値観との整合を支援し、継続的に進化して、より意義のある目標に向かって前進することでしょう。
なお、Skyworkは5月に世界初のdeep researchのAI workspace agentsを発表しており、以下のリンクから体験いただけます:skywork.ai
Media Contact
Company Name: Skywork AI PTE.LTD.
Contact Person: Peter Tian
Email: peter@skywork.ai
State: 2 Science Park Drive
Country: Singapore
Website: skywork.ai
